Here I list my research and course projects over my graduate study.
Research projects
SCREAM: Sketch Resource Allocation for Software-defined Measurement
Paper, Talk, Code
In contrast to flow-based counters, hash-based counters can express many more measurement task types with higher accuracy and can be easily implemented with SRAM memory (cheaper than TCAM). Still a practical hash-based measurement system must handle many concurrent tasks on limited switch resources (SRAM, reporting bandwidth). I developed SCREAM that dynamically allocates resources for hash-based counters. I solved two challenges: (a) estimating the accuracy of tasks by online probabilistic analysis of their output; (b) correctly merging measurement results from different switches using novel techniques. I have implemented three network-wide measurement tasks (heavy hitter, hierarchical heavy hitter and super source / destination detection). Simulations on real-world traces show that SCREAM can support 2x more tasks with higher accuracy than the state-of-the-art static allocation and the same number of tasks with comparable accuracy as an oracle that is aware of future task resource requirements.

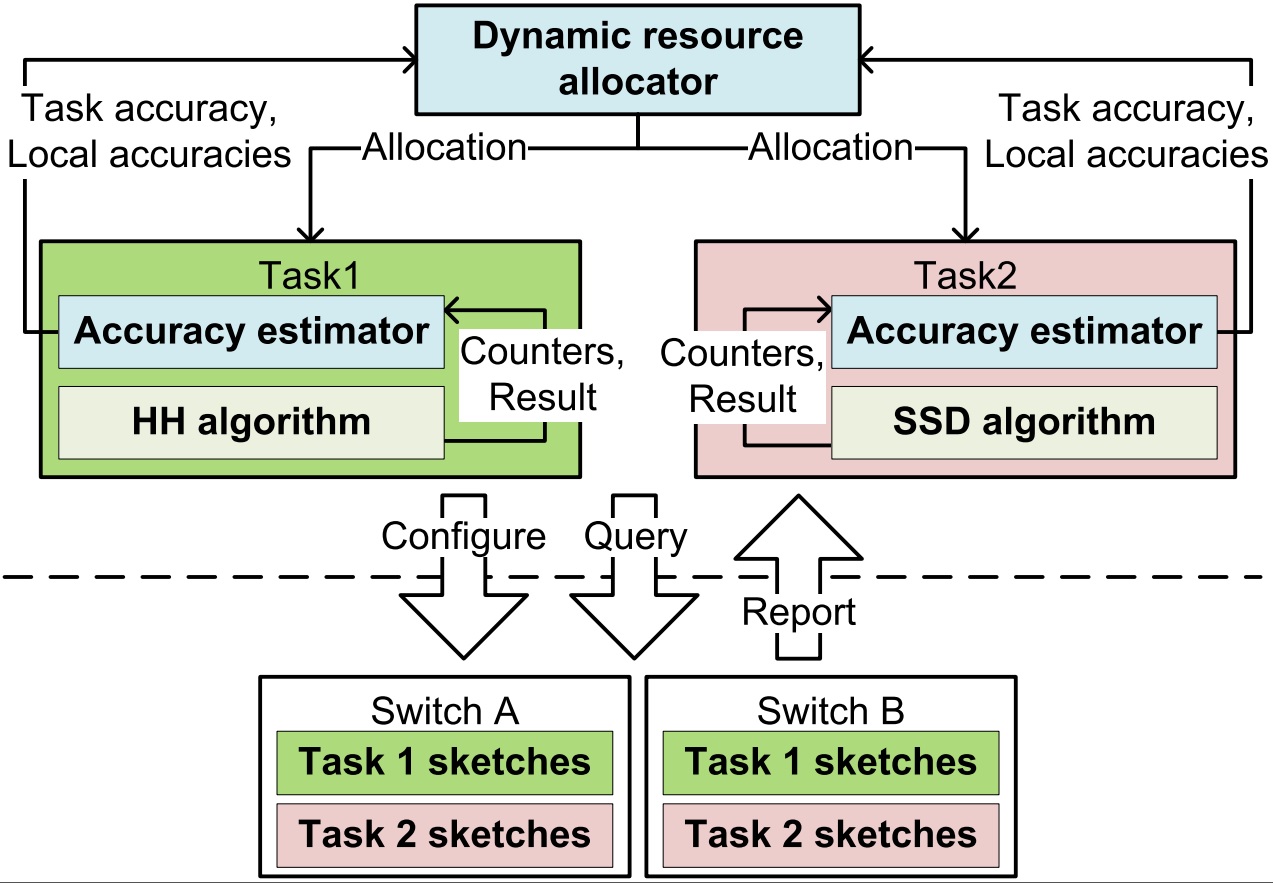
DREAM: Dynamic Resource Allocation for Software-defined Measurement
Paper, Talk, Code
SDN can enable a variety of concurrent, dynamically instantiated, measurement tasks. The measurement tasks use flow counters that monitor traffic in hardware switches using TCAM (ternary content-addressable memory). However, TCAM at switches is expensive and power hungry, and the accuracy of the measurement tasks is a function of the TCAM entries devoted to them on each switch. This function changes with traffic properties, which forces operators to provision for the worst case. My DREAM project provides a measurement framework that abstracts operators from resource limits and provides them with the abstraction of guaranteed measurement accuracy. It dynamically adjusts resources devoted to each measurement task to achieve a desired level of accuracy based on an estimated accuracy feedback from each task. This allows multiplexing TCAM entries temporally and spatially among tasks to support more tasks on limited resources. I proposed new algorithms to solve two challenges in DREAM: (a) accuracy estimation without knowing the ground-truth and (b) fast converging and stable per-switch resource allocation in a scalable way. I built a prototype of DREAM on OpenFlow switches with three network-wide measurement tasks (heavy hitter, hierarchical heavy hitter and change detection), and I showed that DREAM can support 30\% more concurrent tasks with up to 80\% more accurate measurements than fixed allocation

vCRIB: A virtualized Cloud Rule Information Base
Paper, Talk, Code
In SDN, applying many high-level policies such as access control requires many fine-grained rules at switches, but switches have limited rule capacity. This complicates the operator's job as she needs to worry about the constraints on switches. I leveraged the opportunity that there can be different places, on or off the shortest path of flows, to apply rules if we accept some bandwidth overhead and proposed vCRIB to provide operators with the abstraction of a scalable rule storage. vCRIB automatically places rules on hardware switches and end-hosts with enough resources and minimizes the bandwidth overhead. I solved three challenges in its design: 1) Separating overlapping rules may change their semantics, so vCRIB “partitions” overlapping rules to decouple them. 2) vCRIB must pack partitions on switches considering switch resources. I solved this as a new bin-packing problem by a novel approximation algorithm with a proved bound. I modeled the resource usage of rule processing at end-hosts and generalized the solution to both hardware switches and end-hosts. 3) Traffic patterns change over time. vCRIB minimizes traffic overhead using an online greedy algorithm that adaptively changes the location of partitions in the face of traffic changes and VM migration. I demonstrate that vCRIB can find feasible rule placements with less than 10\% traffic overhead when traffic-optimal rule placement is infeasible

Trumpet: Timely Events For Datacenters At End-hosts
With growing concerns of the cost, management difficulty and expressiveness of hardware network switches, there is a new trend of moving measurement and other network functions to software switches at end-hosts. I implemented a subset of measurement algorithms in software to re-evaluate their accuracy and performance for traffic traces with different properties. The results showed that modern multicore computer architectures have significantly increased their cache efficiency and cache size to the extent that it can fit the working set of many measurement tasks with a usually skewed access pattern. As a result, complex algorithms that trade off memory for CPU and access many memory entries to compress the measurement data structure are harmful to packet processing performance. Then I developed an expressive scalable measurement system on servers, Trumpet, that monitors every packet in 10G links with small CPU overhead and reports events in less than 10ms even in the presence of an attack. Trumpet is an event monitoring system in which users define network-wide events, and a centralized controller installs triggers at end-hosts, where triggers run arbitrary codes to test for local conditions that may signal the network-wide events. The controller aggregates these signals and determines if the network-wide event indeed occurred.
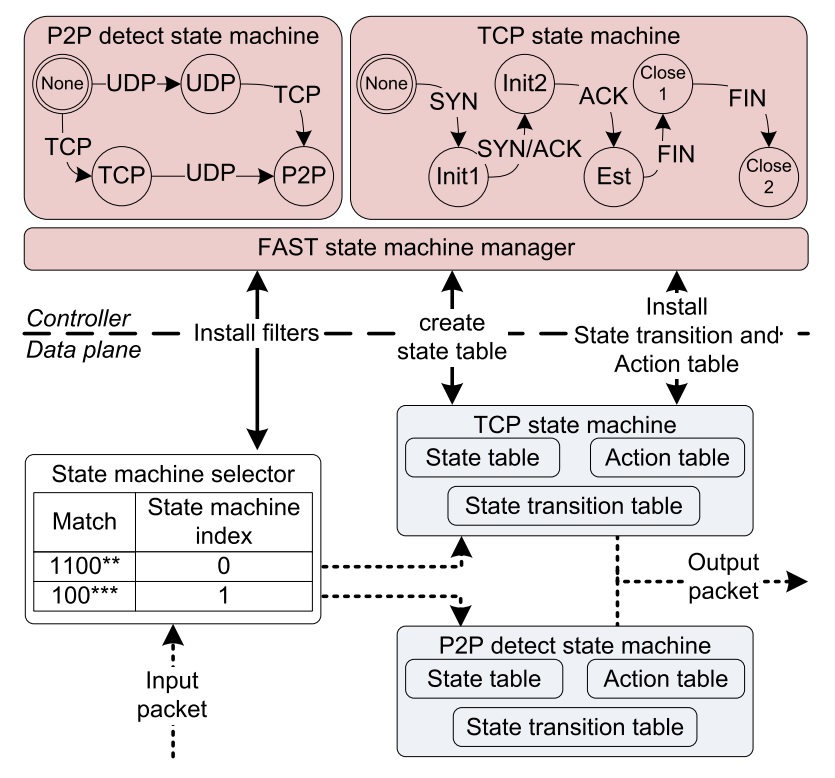
FAST: Flow-level State Transition as a New Switch Primitive for SDN
Paper, Talk
Current SDN interface, OpenFlow, requires the centralized controller to be involved actively in any stateful decision even though the event and action happen on the same switch. This adds 10s of ms delay on packet processing and huge computation overhead on the controller, which makes it hard for operators to implement middlebox functionalities in SDN. I proposed a new control primitive in SDN, flow-level state machines, that enables the controller to proactively program switches to run dynamic actions based on local information without involving the controller. I developed FAST, the controller and the switch architecture using components already available in commodity switches to support the new primitive. This motivated a collaboration with Tsinghua University on HiPPA [9] project that dynamically chains state machines in hardware and software in order to improve the performance of software-based middleboxes and the flexibility of hardware-based ones.
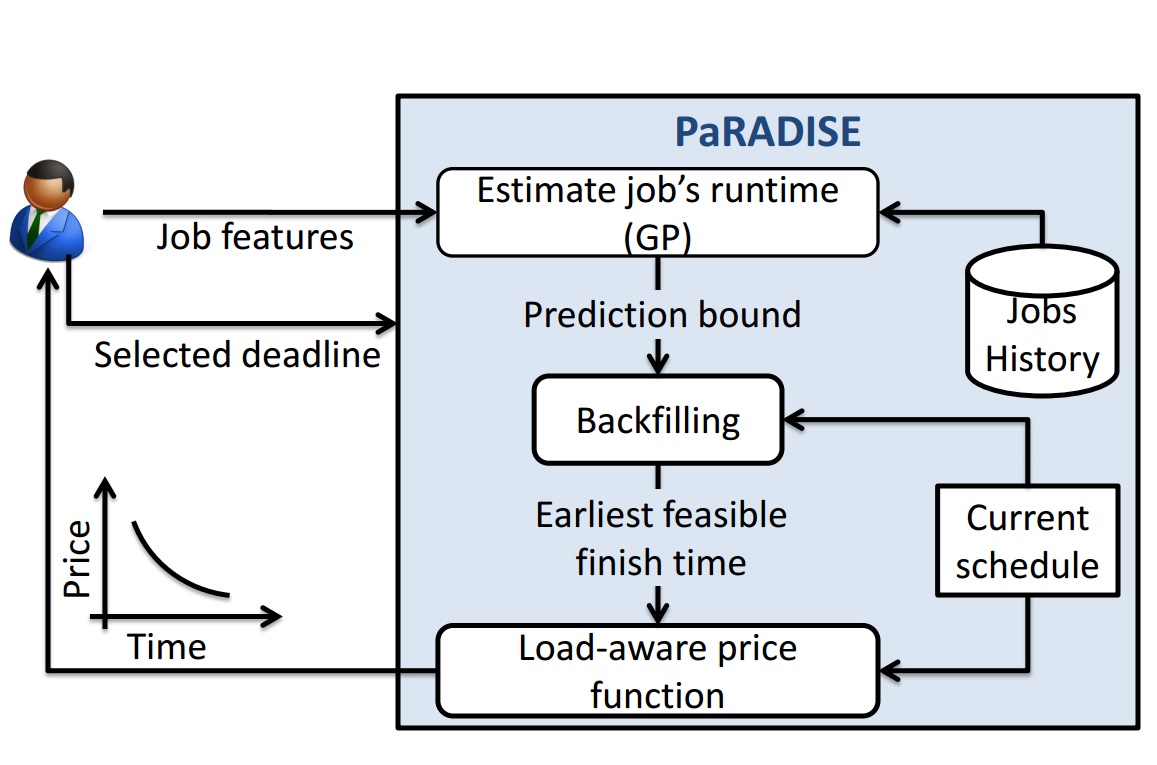
MRM: A service market for Map-Reduce
Data centers are a bunch of computers which are connected through an interconnection network usually offering computing, storage, and … services. On the other hand, the cloud computing model defines a novel role for mobile, social, and health-related computing using the reliability and efficiency of these data centers. As a result of vast application of cloud computing, jobs on these datacenters can have various types with different desired requirements. For example, some jobs are deadline driven while others just only need some computation resources. Duration and the amount of computation needed for each job is not available before running the job while they are important factors in defining the service model to guarantee the quality of service. In this project, first we propose a way to predict job duration in map-reduce framework and then use that to define a deadline-driven service market.
Course projects
- Casebook: implementing simplified post and photo features of Facebook. I used Cassandra as backend database and Python to distribute the load of initializing text search engine and face recognition (using OpenCV). I could load data of 140 users each having 1k posts and 100 photos in 2 minutes using 6 cores and 6 GB RAM on 5 machines in a cluster managed by OpenStack. Project definition,Project reports,
- Analyzing properties of a 0.5TB (a billion vertices) RDF graph using Pig/Hadoop on Amazon EC2 for Introduction to Data Sciences course on Coursera. The goal of this project in Introduction to Data Science course on Coursera.com was to compute the histogram and walk on the graph as an introductory step to Pig and Amazon EC2.
- Digit Recognition: The project is about recognizing the digits from the tags of participants in a competition. I have tried different feature such as raw pixels, edges, filled edges, Hough space, and Gradient Map for multiple classification algorithms such as linear perceptron (as base), KNN and SVM. The best result is for SVM classifier on the Gradient Map features space of 32*32 pixel images. SVM parameters have been optimized using the 5 fold cross validation in libSVM library. Based on what I saw in this project, the selected features are very important to get the good results and sometimes because of the imperfection of the dataset some intuitive features may not work. Besides, each classifier algorithm may work well with a specific feature set. Moreover, adding new features will not always increase the accuracy.
- Queueing analysis and simulation of a VOIP system in three levels of details: Call, Voice spurt and Packet. Project definition,Project report.
- A C compiler: Given the grammar of a simplified C programming language, we should use LEX and YACC to parse the input program, type check, find initial memory usage and generate 3-address instructions. Project definition (0,1,2),Codes Δ, 3-address-simulator.
Old projects
- MobiSim: Design and implementation of a mobility model simulator and analyzer in mobile ad-hoc networks. Project page
- LayeredCast: A hybrid peer-to-peer architecture for real-time layered video streaming over Internet. Project page